 veth-pair容器中的网络
veth-pair容器中的网络
# veth-pair 容器中的网络
# 是什么
veth-pair(虚拟以太网对)是一种虚拟网络设备。 它在 Linux 内核中用于连接不同的网络命名空间,实现网络通信。veth-pair由一对虚拟以太网接口组成,一般成对出现,它们在逻辑上是相互连接的,一端连着下一站,一端彼此相连着,可以在不同的命名空间或进程之间传递网络数据包。
正因为有这个特性,它常常充当着一个桥梁,连接着各种虚拟网络设备,典型的例子像“两个 namespace 之间的连接”,“Bridge、OVS 之间的连接”,“Docker 容器之间的连接” 等等。
# veth-pair的配置
# 创建veth-pair
我们可以使用ip命令设置veth-pair,并将其设置在不同的namespace。
命令格式:
sudo ip link add {veth1名称} type veth peer name {veth2名称}
例如创建一个veth-pair:veth0-veth1:
$ sudo ip link add veth0 type veth peer name veth1
6: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d2:0f:6d:88:46:6f brd ff:ff:ff:ff:ff:ff
7: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether f6:fd:cc:8c:ca:bc brd ff:ff:ff:ff:ff:ff
2
3
4
5
6
7
# 将veth设置为UP
创建的veth-pair默认是DOWN状态,是无法使用的,需要设置为UP:
$ sudo ip link set veth0 up
$ sudo ip link set veth1 up
2
# 配置IP
为veth0和veth1分别配上 IP:30.1.1.10和30.1.1.11
$ sudo ip addr add 30.1.1.10/24 dev veth0
$ sudo ip addr add 30.1.1.11/24 dev veth1
6: veth1@veth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d2:0f:6d:88:46:6f brd ff:ff:ff:ff:ff:ff
inet 30.1.1.11/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::d00f:6dff:fe88:466f/64 scope link
valid_lft forever preferred_lft forever
7: veth0@veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether f6:fd:cc:8c:ca:bc brd ff:ff:ff:ff:ff:ff
inet 30.1.1.10/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::f4fd:ccff:fe8c:cabc/64 scope link
valid_lft forever preferred_lft forever
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# veth的通信流程
# 网络连通性
尝试在veth之间 ping,从veth0 ping veth1:
$ ping -I veth0 30.1.1.11 -c 3
PING 30.1.1.11 (30.1.1.11) from 30.1.1.10 veth0: 56(84) bytes of data.
From 30.1.1.10 icmp_seq=1 Destination Host Unreachable
From 30.1.1.10 icmp_seq=2 Destination Host Unreachable
From 30.1.1.10 icmp_seq=3 Destination Host Unreachable
--- 30.1.1.11 ping statistics ---
3 packets transmitted, 0 received, +3 errors, 100% packet loss, time 2043ms
pipe 3
2
3
4
5
6
7
8
9
从结果可知,veth0和veth1之间网络不可达;明明是同网段的 IP,为什么不通呢?。
排查网络问题可以通过抓包的方式解决:
# tcpdump -nnt -i veth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
ARP, Request who-has 30.1.1.11 tell 30.1.1.10, length 28
ARP, Request who-has 30.1.1.11 tell 30.1.1.10, length 28
ARP, Request who-has 30.1.1.11 tell 30.1.1.10, length 28
2
3
4
5
6
可以看到,由于veth0和veth1处于同一个网段,且是第一次连接,所以会事先发ARP包,但veth1并没有响应ARP包。
经查阅,这是由于使用的 Ubuntu 系统内核中一些 ARP 相关的默认配置限制所导致的,需要修改一下配置项:
echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local
echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local
echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
2
3
4
5
修改完再 ping 就通了:
$ ping -I veth0 30.1.1.11 -c 3
PING 30.1.1.11 (30.1.1.11) from 30.1.1.10 veth0: 56(84) bytes of data.
64 bytes from 30.1.1.11: icmp_seq=1 ttl=64 time=0.092 ms
64 bytes from 30.1.1.11: icmp_seq=2 ttl=64 time=0.048 ms
64 bytes from 30.1.1.11: icmp_seq=3 ttl=64 time=0.050 ms
--- 30.1.1.11 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2025ms
rtt min/avg/max/mdev = 0.048/0.063/0.092/0.020 ms
2
3
4
5
6
7
8
9
那么为什么需要修改这些内核参数的默认配置项呢?这些配置项又代表什么?
/proc/sys/net/ipv4/conf/veth1/accept_local:用于控制网络接口是否接受本地源地址的数据包(此处控制veth1接口)。- 1:表示接受
- 0:拒绝接受本地源地址的数据包
/proc/sys/net/ipv4/conf/all/rp_filter:用于控制 Linux 系统对接收数据包的源地址验证(反向路径过滤,reverse path filter),以防止网络欺骗。0:关闭反向路径过滤
作用:系统不会对接收数据包的源地址进行严格的路径验证。这在一些复杂的网络环境中可能是有用的,例如当存在多个网络接口且数据包可能通过不同路径到达时,但同时也可能会增加系统遭受某些类型的网络攻击(如 IP 欺骗攻击)的风险。
1:开启松散的反向路径过滤
作用:系统会进行一定程度的源地址验证。如果数据包的源地址所对应的网络接口与系统根据路由表认为该数据包应该到达的网络接口不匹配,系统可能会对数据包进行一些限制处理,但不是绝对地丢弃数据包。这种设置在大多数正常的网络环境中可以提供一定的安全性,同时也能适应一些常见的网络变化情况。
2:开启严格的反向路径过滤
作用:系统会严格按照路由表对接收数据包的源地址进行验证。如果数据包的源地址所对应的网络接口与系统认为该数据包应该到达的网络接口不一致,系统会直接丢弃该数据包。这可以有效地防止 IP 欺骗攻击,但在某些复杂的网络环境中可能会导致一些正常的数据包被误丢弃,例如在存在动态路由变化或多路径网络的情况下。
/proc/sys/net/ipv4/conf/veth0/rp_filter:跟上述一致。
# 通信流程
从tcpdump抓包的结果可知,veth0只发起了 PING 请求,并没有看到veth1的回包:
# tcpdump -nnt -i veth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
IP 30.1.1.10 > 30.1.1.11: ICMP echo request, id 9, seq 1, length 64
IP 30.1.1.10 > 30.1.1.11: ICMP echo request, id 9, seq 2, length 64
IP 30.1.1.10 > 30.1.1.11: ICMP echo request, id 9, seq 3, length 64
2
3
4
5
6
再从veth1侧抓包,仅抓到了30.1.1.10到30.1.1.11发起的 PING 请求,也没有看到回包:
# tcpdump -nnt -i veth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
IP 30.1.1.10 > 30.1.1.11: ICMP echo request, id 13, seq 1, length 64
IP 30.1.1.10 > 30.1.1.11: ICMP echo request, id 13, seq 2, length 64
IP 30.1.1.10 > 30.1.1.11: ICMP echo request, id 13, seq 3, length 64
2
3
4
5
6
从上面可知,PING 请求的回包并没有经过veth1,那么它是经过哪里回报的呢?
tcpdump -nnt -i lo
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on lo, link-type EN10MB (Ethernet), snapshot length 262144 bytes
IP 30.1.1.11 > 30.1.1.10: ICMP echo reply, id 17, seq 1, length 64
IP 30.1.1.11 > 30.1.1.10: ICMP echo reply, id 17, seq 2, length 64
IP 30.1.1.11 > 30.1.1.10: ICMP echo reply, id 17, seq 3, length 64
2
3
4
5
6
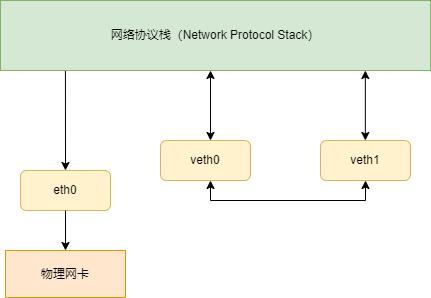
我们看下整个通信流程就明白了。
- 首先 ping 程序构造 ICMP
echo request,通过 socket 发给协议栈。 - 由于 ping 指定了走 veth0 口,如果是第一次,则需要发 ARP 请求,否则协议栈直接将数据包交给 veth0。
- 由于 veth0 连着 veth1,所以 ICMP request 直接发给 veth1。
- veth1 收到请求后,交给另一端的协议栈。
- 协议栈看本地有 30.1.1.11 这个 IP,于是构造 ICMP reply 包,查看路由表,发现回给 30.1.1.0/24 网段的数据包应该走 localback 口,于是将 reply 包交给 lo 口(会优先查看路由表的 0 号表,
ip route show table 0查看)。 - lo 收到协议栈的 reply 包后,啥都没干,转手又回给协议栈。
- 协议栈收到 reply 包之后,发现有 socket 在等待包,于是将包给 socket。
- 等待在用户态的 ping 程序发现 socket 返回,于是就收到 ICMP 的 reply 包。
整个过程如图所示:

# veth-pair 的使用方式
这里以 network namespace 中间的通信作为例子。namespace 是 Linux 2.6.x 内核版本之后支持的特性,主要用于资源的隔离。有了 namespace,一个 Linux 系统就可以抽象出多个网络子系统,各子系统间都有自己的网络设备,协议栈等,彼此之间互不影响。
如果各个 namespace 之间需要通信,怎么办呢,答案就是用 veth-pair 来做桥梁。
根据连接的方式和规模,可以分为直接相连,通过 Bridge 相连 和 通过 OVS 相连。
# 直接相连
直接相连是最简单的方式,如下图,一对 veth-pair 直接将两个 namespace 连接在一起。

给 network namespace 配置 veth-pair,并测试连通性:
创建 network namespace
$ sudo ip netns a ns1 $ sudo ip netns a ns21
2创建 veth-pair
$ sudo ip link add veth0 type veth peer name veth11将 veth0、veth1 分别加入 ns1 和 ns2
$ sudo ip link set veth0 netns ns1 $ sudo ip link set veth1 netns ns21
2配置 IP 并启用
$ sudo ip netns exec ns1 ip address add 30.1.1.10/24 dev veth0 $ sudo ip netns exec ns1 ip link set veth0 up $ sudo ip netns exec ns2 ip address add 30.1.1.11/24 dev veth1 $ sudo ip netns exec ns2 ip link set veth1 up1
2
3
4
5从 namespace ns1 的 veth0 ping namespace ns2 的 veth1
$ sudo ip netns exec ns1 ping 30.1.1.11 -c 3 PING 30.1.1.11 (30.1.1.11) 56(84) bytes of data. 64 bytes from 30.1.1.11: icmp_seq=1 ttl=64 time=0.035 ms 64 bytes from 30.1.1.11: icmp_seq=2 ttl=64 time=0.048 ms 64 bytes from 30.1.1.11: icmp_seq=3 ttl=64 time=0.054 ms --- 30.1.1.11 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2044ms rtt min/avg/max/mdev = 0.035/0.045/0.054/0.007 ms1
2
3
4
5
6
7
8
9
# 通过 Bridge 相连
Linux Bridge 相当于一台交换机,可以中转两个 namespace 的流量,veth-pair 相当于交换机两个口的连线。
如下图,两对 veth-pair 分别将两个 namespace 连到 Bridge 上。
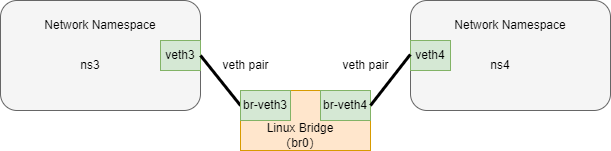
给 network namespace 配置 veth-pair,并测试连通性:
参加 Bridge br0 并启用
$ sudo ip link add br0 type bridge $ sudo ip link set br0 up1
2创建 veth-pair
$ sudo ip link add veth3 type veth peer br-veth3 $ sudo ip link add veth4 type veth peer br-veth41
2创建两个 network namespace
$ sudo ip netns add ns3 $ sudo ip netns add ns41
2将 veth-pair 加入 namespace
$ sudo ip link set veth3 netns ns3 $ sudo ip link set br-veth3 master br0 $ sudo ip link set br-veth3 up $ sudo ip link set veth4 netns ns4 $ sudo ip link set br-veth4 master br0 $ sudo ip link set br-veth4 up1
2
3
4
5
6
7给两个 ns 中的 veth 配置 IP 并启用
$ sudo ip netns exec ns3 ip address add 30.1.1.3/24 dev veth3 $ sudo ip netns exec ns3 ip link set veth3 up $ sudo ip netns exec ns4 ip address add 30.1.1.4/24 dev veth4 $ sudo ip netns exec ns4 ip link set veth4 up1
2
3
4
5从 namespace ns3 的 veth3 ping namespace ns4 的 veth4
$ sudo ip netns exec ns3 ping 30.1.1.4 -c 3 PING 30.1.1.4 (30.1.1.4) 56(84) bytes of data. 64 bytes from 30.1.1.4: icmp_seq=1 ttl=64 time=0.036 ms 64 bytes from 30.1.1.4: icmp_seq=2 ttl=64 time=0.070 ms 64 bytes from 30.1.1.4: icmp_seq=3 ttl=64 time=0.060 ms --- 30.1.1.4 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2030ms rtt min/avg/max/mdev = 0.036/0.055/0.070/0.014 ms1
2
3
4
5
6
7
8
9
这里有条需要说明的命令:ip link set br-veth3 master br0。这条命令的作用是将虚拟网络接口br-veth3设置为网桥br0的从属设备,即将br-veth3与br0关联起来,使得br-veth3所连接的网络流量可以通过br0进行转发和处理。
# 通过 OVS 相连
OVS 是第三方开源的 Bridge,功能比 Linux Bridge 要更强大。

给 network namespace 配置 veth-pair,并测试连通性:
安装 ovs
$ sudo apt-get install openvswitch-switch -y $ sudo ovs-vsctl show 19efc152-1c69-4302-b1a3-05ac132e12eb ovs_version: "2.17.0"1
2
3
4创建 ovs bridge(注意需要安装 ovs)
$ sudo ovs-vsctl add-br ovs-br # sudo ip link set ovs-br up # 以下为刚刚创建的 ovs-br 17: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 92:62:93:20:a2:7d brd ff:ff:ff:ff:ff:ff 18: ovs-br: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether fe:c4:d7:75:c4:4c brd ff:ff:ff:ff:ff:ff1
2
3
4
5
6
7
8创建 veth-pair
$ sudo ip link add veth5 type veth peer ovs-veth5 $ sudo ip link add veth6 type veth peer ovs-veth61
2创建两个 network namespace
$ sudo ip netns add ns5 $ sudo ip netns add ns61
2将 veth-pair 两端分别加入到 ns 和 ovs bridge 中
$ sudo ip link set veth5 netns ns5 $ sudo ovs-vsctl add-port ovs-br ovs-veth5 $ sudo ip link set ovs-veth5 up $ sudo ip link set veth6 netns ns6 $ sudo ovs-vsctl add-port ovs-br ovs-veth6 $ sudo ip link set ovs-veth6 up1
2
3
4
5
6
7给 ns 中的 veth 配置 IP 并启用
$ sudo ip netns exec ns5 ip address add 30.1.1.5/24 dev veth5 $ sudo ip netns exec ns5 ip link set veth5 up $ sudo ip netns exec ns6 ip address add 30.1.1.6/24 dev veth6 $ sudo ip netns exec ns6 ip link set veth6 up1
2
3
4
5从 namespace ns5 的 veth5 ping namespace ns6 的 veth6
$ sudo ip netns exec ns6 ping 30.1.1.6 -c 31
# 应用场景
veth-pair 在实际应用中的常见场景包括:
- 容器技术:在容器环境中,veth-pair 常用于连接容器与宿主机的网络。例如 Docker 容器,通过 veth-pair 可以让容器之间建立虚拟网络并互相通信。其一端在容器网络栈内充当 eth0 网卡,另一端在宿主机上充当虚拟网卡,该虚拟网卡可以“插”在 Docker0 网桥或其他网桥上。
- 网络命名空间(network namespace):可用于连接不同的网络命名空间,实现不同命名空间之间的网络连接。
- 构建复杂虚拟网络:veth-pair 可以充当桥梁,连接各种虚拟网络设备,从而构建出非常复杂的虚拟网络结构。例如,在一些测试或仿真场景中,通过 veth-pair 连接不同的网络组件,以满足特定的网络需求。
- 与网桥结合:将 veth-pair 设备的一端与 linux bridge 相连接,一旦有网络设备与 linux bridge 相连,就会触发 linux bridge 的一个功能,与 linux bridge 相连的网络设备不再向网络协议栈发送数据,转而发送给 linux bridge。
- 在 Kubernetes 中的应用:Kubernetes 网络中也会用到 veth-pair 技术。例如在跨物理机的容器网络通信中,通过 flannel 进程中转或使用 vxlan 等方式,结合 veth-pair 实现容器之间的通信。
# 参考
- https://www.opencloudblog.com/?p=66
- https://segmentfault.com/a/1190000009251098