 深入理解 sync.Pool
深入理解 sync.Pool
# sync 包 —— Pool
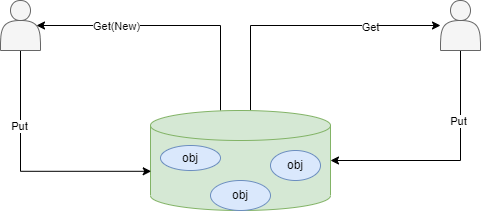
为了减少 GC,重用对象,go 提供了对象重用的机制,也就是sync.Pool对象池。 sync.Pool是可伸缩的,并发安全的。其大小仅受限于内存的大小,可以被看作是一个存放可重用对象的值的容器。 设计的目的是存放已经分配的但是暂时不用的对象,在需要用到的时候直接从pool中取。
sync.Pool的大小是可伸缩的,高负载时会动态扩容,存放在池中的对象如果不活跃了会被自动清理。
一句话总结:保存和复用临时对象,减少内存分配,降低 GC 压力。
# sync.Pool 的使用
这里使用sync.Pool复用了结构体Student,当使用到Student时可以直接用Pool中获取,而不需要频繁地创建。
type Student struct {
Name string
}
func TestPool(t *testing.T) {
p := sync.Pool{
New: func() any {
// 创建函数, sync.Pool 会回调,用于创建对象
t.Log("创建一个对象")
return Student{}
},
}
for i := 0; i < 10; i++ {
// 从 Pool 中取出对象
// 1. 如果 Pool 没有,会调用 New() 创建一个然后返回
// 2. 如果 Pool 有对象,则直接返回
obj := p.Get().(Student)
// 用完对象后需要放回去
p.Put(obj)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
sync.Pool会先查看自己是否有资源,有则直接返回- 没有则创建一个新的
sync.Pool会在 GC 的时候释放缓存的资源
使用sync.Pool一般都是为了复用内存:
- 可以减少内存的分配,也就减轻了 GC 压力(最主要)
- 减少消耗 CPU 资源(内存分配和 GC 都是 CPU 密集操作)
# Pool 的实现
如果我们自己需要实现类似功能的Pool,那么可以用什么方案呢?
最简单的方案,就是用队列(go 可以使用 channel),而且是并发安全的队列。队头取,队尾放回去。在队列为空的时候创建一个新的。问题是:Pool一般都用于并发环境,队头和队尾都是竞争点,依赖于锁;很显然,全局锁将会成为瓶颈。

由于全局锁会成为瓶颈,我们就避免全局锁,可以考虑使用TLB(thread-local-buffer)。每个线程搞一个队列,再维护一个全局共享的队列。
但是 Go 有更好的选择。Go 本身的 GPM 调度模型,其中 P 代表的是处理器(Processor)。
P 的优点:任何数据绑定在 P 上,都不需要竞争,因为 P 同一事件只有一个 G(Goroutine) 在运行。
同时,Go 并没有采用全局共享队列的方案,而是采用了窃取的方案。
# sync.Pool 的设计

- 每个 P 一个
poolChain对象 - 每个
poolChain有一个private和shared shared指向的是一个poolChain。poolChain的数据会被别的 P 给偷走poolChain是一个链表 +ring buffer的双重结构- 从整体上来说,它是一个双向链表
- 从单个节点来说,它指向了一个
ring buffer。后一个节点的ring buffer的长度是前一个节点的两倍。
ring buffer优势(也可以说是数组的优势):
- 一次性分配好内存,循环利用
- 对缓存友好
sync.Pool的定义:
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() any
}
2
3
4
5
6
7
8
9
10
11
12
13
14
poolChain、poolChainElt和poolDequeue的定义:
type poolDequeue struct {
headTail uint64
vals []eface
}
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
next, prev *poolChainElt
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Get 的步骤
- 看
private可不可用,可用就直接返回 - 不可用则从自己的
poolChain里面尝试获取一个- 从头开始找。注意,头指向的其实是最近创建的 ring buffer
- 从队头往队尾找
- 找不到则尝试从别的 P 里面偷一个出来。
- 偷的过程就是全局并发,因为理论上来说,其它 P 都可能恰好一起来偷了
- 偷是从队尾开始偷的
- 如果偷也偷不到,那么就会去找
victim的 - 连
victim的也没有,那就去创建一个新的
func (p *Pool) Get() any {
if race.Enabled {
race.Disable()
}
l, pid := p.pin()
x := l.private // 1.先从 private 拿
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead() // 2.private 不可用就从 poolChain 的队头拿
if x == nil {
x = p.getSlow(pid) // 3.尝试偷或者从 victim 拿
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil { // 4.连 victim 没有,就创建回调 New 创建一个
x = p.New()
}
return x
}
func (p *Pool) getSlow(pid int) any {
// See the comment in pin regarding ordering of the loads.
size := runtime_LoadAcquintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
for i := 0; i < int(size); i++ { // 尝试从别的 G 偷
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Try the victim cache. We do this after attempting to steal
// from all primary caches because we want objects in the
// victim cache to age out if at all possible.
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim // 从 victim 拿
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Mark the victim cache as empty for future gets don't bother
// with it.
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
偷是一个全局竞争的过程,但是找victim不是,找victim和找正常的是一样的过程。为什么poolChain找不到时,先从别 P 里偷,而不是先从victim拿?
从注释里可以看出:因为sync.Pool希望victim里面的对象尽可能被回收掉。
# Put 的步骤
private要是没放东西,就直接放private- 否则,准备放
poolChain- 如果
poolChain的HEAD还没有创建,就创建一个HEAD,然后创建一个容量为 8 的ring buffer,把数据丢过去 - 如果
poolChain的HEAD指向的ring buffer没满,则往ring buffer放 - 如果
poolChain的HEAD指向的ring buffer已经满了,就创建一个新的节点,并且创建一个两倍容量大小的ring buffer,再把数据丢过去
- 如果
# Pool 与 GC
正常情况下,我们设计一个 Pool 都要考虑容量和淘汰问题(基本类似于缓存):
- 能够控制住 Pool 的内存消耗量
- 在这个前提下,考虑淘汰的问题
Go 的sync.Pool则不同,它纯粹依赖于 GC,用户完全没办法手工控制。
sync.Pool的核心机制是依赖于两个:locals和victim
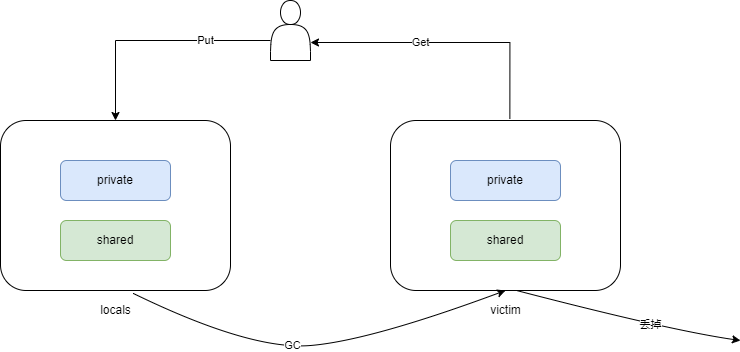
GC 的过程也很简单:
locals会被挪过去变成victimvictim会被直接回收掉
复活:如果victim的对象再次被使用,那么它就会被丢回去locals,逃过了下一轮被 GC 回收掉的命运
优点:防止 GC 引起性能抖动
# poolLocal 和 false sharing
每一个poolLocal都有一个p~ad字段,是用于将poolLocal所占用的内存补齐到 128 的整数倍。
在并发话题下:所有的对齐基本上都是为了独占 CPU 高速缓存的CacheLine。
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
2
3
4
5
6
7
# 总结
sync.Pool是 Go 提供的一个用于缓解 GC 压力,复用对象的对象池sync.Pool的作用是:保存和复用临时对象,减少内存分配,降低 GC 压力sync.Pool内部分为private和shared两个结构,其中shared是可以被其他 P 偷的Get的步骤:先从private拿,拿不到就从shared的poolLocal拿,如果还拿到,就别的 P 里盗取,盗不到的话就去victim捞,最后再回调New创建Put的步骤:先给尝试往private放,放不了就往shared的poolLocal里放,如果poolChain的HEAD还没有创建,就创建一个HEAD,然后创建一个容量为 8 的ring buffer,把数据丢过去